代码:
def proxy_get_content_stream(url):
if is_use_proxy:
socks.set_default_proxy(socks.SOCKS5, PROXY_HOST, PROXY_PORT)
socket.socket = socks.socksocket
return requests.get(url, headers=HEADERS, stream=True, timeout=300)
def save_image_from_url_with_progress(url, cnt):
with closing(proxy_get_content_stream(url)) as response:
chunk_size = 1024 # 单次请求最大值
content_size = int(response.headers['content-length']) # 内容体总大小
data_count = 0
with open(cnt, "wb") as file:
for data in response.iter_content(chunk_size=chunk_size):
file.write(data)
data_count = data_count + len(data)
now_position = (data_count / content_size) * 100
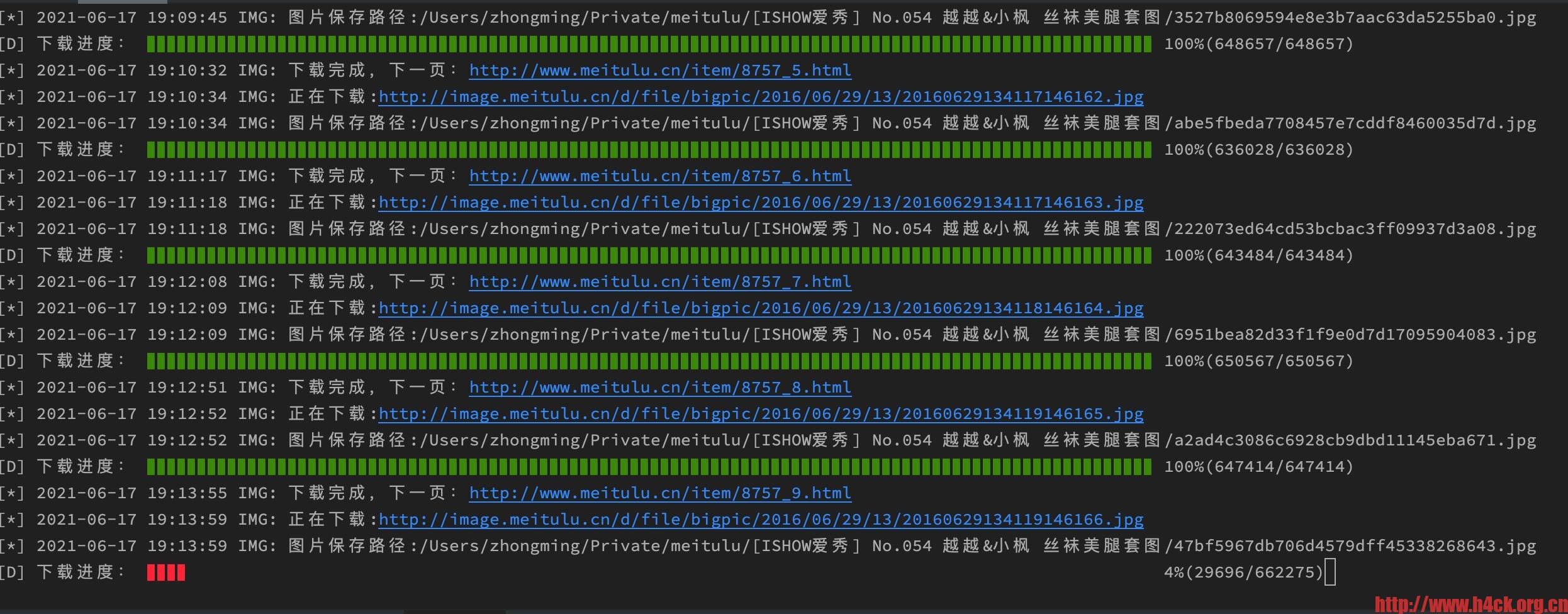
print("\r[D] 下载进度: %s %d%%(%d/%d)" % (int(now_position) * '▊' + (100 - int(now_position)) * ' ',
now_position,
data_count,
content_size,), end=" ")
print('')